Unlocking Efficiency: How Hugging Face’s TOON Data Format Cuts LLM Token Usage by Up to 60%
In the rapidly evolving world of artificial intelligence, large language models (LLMs) are becoming central to countless applications. Yet, one persistent challenge remains — the cost of token usage. Every token processed translates directly into operational expenses, especially when working with structured data like logs, lists, and tables. Hugging Face’s newly introduced TOON data format offers a revolutionary solution, promising to reduce token consumption by 30 to 60%. This advancement could be transformative for businesses relying heavily on LLM pipelines.
What is TOON and Why Does It Matter?
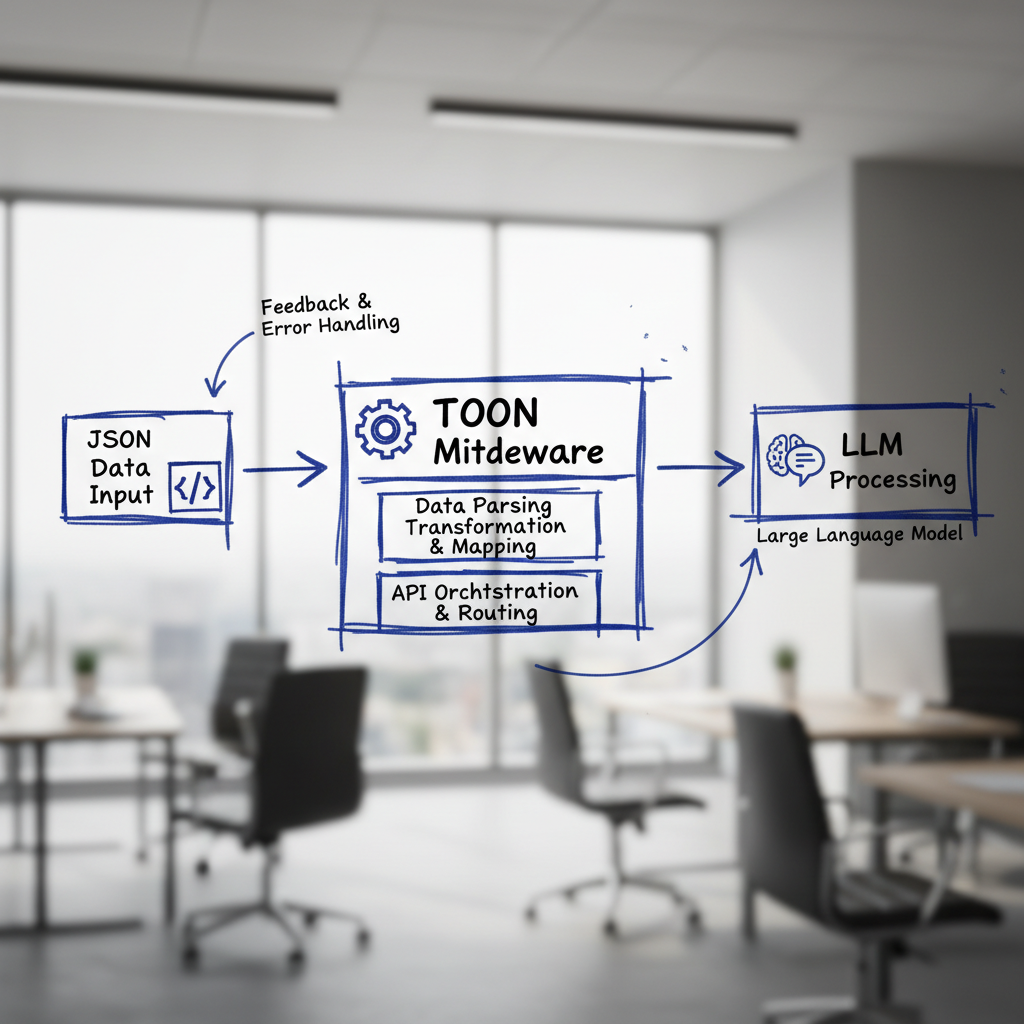
TOON is a specialized data format developed by Hugging Face designed specifically to optimize input for large language models. Essentially, it’s a middleware layer that converts JSON structured data into a more token-efficient format right before the data reaches the model. By doing this, TOON reduces the number of tokens needed to represent complex or voluminous structured data, resulting in substantial cost savings.
The Token Cost Problem
Token usage directly impacts your budget when interacting with LLMs, as providers charge based on the number of tokens processed. Traditional data formats like JSON, while universally used and easy to integrate, can be inefficient in token-heavy contexts because they include numerous unnecessary syntactic elements — brackets, commas, and quotes — which add to token count without providing semantic value for the model.
How TOON Tackles This Issue
TOON was crafted for the reality of LLM workloads focusing on structured data types — including logs, lists, and tables. Instead of sending verbose JSON strings, TOON encodes this information in a concise format that maintains structure and meaning while minimizing token count. This middleware approach allows developers to simply convert existing JSON data to TOON just before the input stage without overhauling their existing infrastructure.
Real-World Applications and Benefits
Implementing TOON can have significant benefits, especially for companies operating at scale where token costs can spiral quickly.
Cost Efficiency and Scalability
For organizations pushing large volumes of structured data through LLMs — for example, analyzing logs for security or operational insights, processing table data for business intelligence, or working with extensive lists — a 30% to 60% reduction in token usage can turn previously unsustainable pipelines into profitable ones.
Simple Integration: Middleware Advantage
The beauty of TOON lies in its simplicity. It acts as middleware, which means you can integrate it into your existing data processing pipelines without a major rewrite. Simply convert JSON data to TOON format immediately before passing the data to the model. This minimizes disruption and maximizes the returns in token savings.
Example Workflow Using TOON
// Pseudo code example of converting JSON to TOON
const jsonData = { "name": "Alice", "age": 30, "skills": ["Python", "Machine Learning"] };
const toonData = convertJSONtoTOON(jsonData);
const modelResponse = await runLLMModel(toonData);
In this example, convertJSONtoTOON is the middleware function handling the conversion, effectively reducing the token payload before the data is fed into the model.
Tracking Your Token Usage and Budget
If you’re regularly pushing structured data through LLMs, keeping a close eye on your token consumption is essential. Tools and APIs often provide token usage metrics, but what you do with that data can be the difference between staying profitable and suffering losses.
Ask yourself:
- What data formats am I sending to my LLMs?
- Are large sections of my input data redundant or inefficiently formatted?
- Could middleware solutions like TOON be integrated to streamline my token usage?
With TOON, you gain a practical answer to these questions, unlocking a pathway to more cost-effective and scalable AI workflows.
Conclusion: A Potential Game-Changer for AI at Scale
Although still in the early stages, Hugging Face’s TOON data format represents a promising leap forward in managing LLM costs related to structured data inputs. By cutting token usage between 30% and 60%, it offers a clear financial incentive to adopt this middleware approach. For AI teams and businesses scaling their natural language processing workloads, TOON may well become a game-changer — optimizing budgets, improving efficiency, and enabling broader experimentation without breaking the bank.
Keep an eye on this development, experiment with TOON in your pipelines, and be prepared to rethink how structured data is fed into your LLM models.
For more details on TOON and to stay updated on AI innovations, visit Hugging Face’s official website.
