Token-Kosten sind einer der größten Kostentreiber beim Betrieb von LLM-Pipelines im großen Maßstab. Jedes verarbeitete Token schlägt direkt auf die Rechnung – besonders bei strukturierten Daten wie Logs, Listen und Tabellen, die traditionell ineffizient kodiert werden. Hugging Faces neues TOON-Datenformat setzt genau hier an und verspricht eine Reduktion des Token-Verbrauchs um 30 bis 60 %.
Was ist TOON und warum ist es relevant?
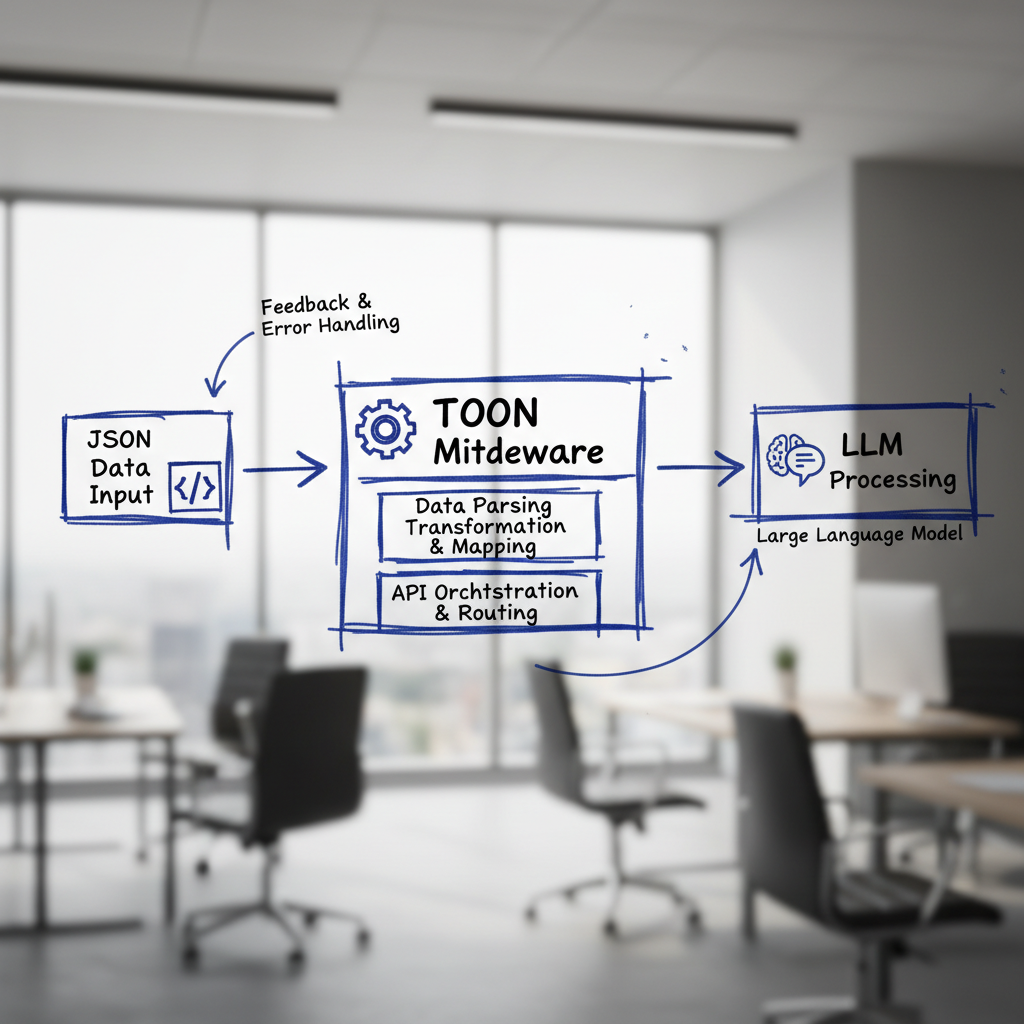
TOON ist ein spezialisiertes Datenformat von Hugging Face, das strukturierte Daten token-effizient kodiert, bevor sie an ein Sprachmodell übergeben werden. Es fungiert als Middleware-Schicht: Bestehende JSON-Daten werden unmittelbar vor der Modell-Eingabe konvertiert – ohne dass die dahinterliegende Infrastruktur angepasst werden muss.
Das Token-Kosten-Problem
Traditionelle Formate wie JSON sind universell und einfach zu integrieren – aber token-ineffizient. Klammern, Anführungszeichen und Kommas erhöhen die Token-Anzahl, ohne dem Modell zusätzliche semantische Information zu liefern. Bei großen Datenmengen summiert sich das schnell.
Wie TOON das Problem löst
TOON wurde speziell für LLM-Workloads entwickelt, die mit strukturierten Datentypen arbeiten – Logs, Listen, Tabellen. Anstatt ausführliche JSON-Strings zu übergeben, kodiert TOON die Information kompakt, behält dabei aber Struktur und Bedeutung bei. Das Ergebnis: weniger Token, gleicher Informationsgehalt.
Anwendungsfälle und Vorteile
Kosteneffizienz im großen Maßstab
Für Unternehmen, die große Mengen strukturierter Daten durch LLMs verarbeiten – etwa Log-Analyse für Security, Tabellenauswertung für Business Intelligence oder Listen-Verarbeitung – kann eine Reduktion von 30–60 % zuvor unrentable Pipelines wirtschaftlich machen.
Einfache Integration als Middleware
TOON lässt sich in bestehende Datenpipelines einfügen, ohne sie grundlegend zu verändern. Die Konvertierung geschieht als letzter Schritt vor der Modellübergabe:
// Pseudocode: JSON zu TOON konvertieren
const jsonData = { "name": "Alice", "age": 30, "skills": ["Python", "Machine Learning"] };
const toonData = convertJSONtoTOON(jsonData);
const modelResponse = await runLLMModel(toonData);Token-Nutzung im Blick behalten
Wer regelmäßig strukturierte Daten an LLMs übergibt, sollte den eigenen Token-Verbrauch aktiv überwachen. Relevante Fragen dabei:
- Welche Datenformate werden aktuell an das Modell übergeben?
- Gibt es redundante oder unnötig aufgeblähte Eingaben?
- Wo lässt sich Middleware wie TOON einsetzen, um Token zu sparen?
Fazit
TOON befindet sich noch in einer frühen Phase, zeigt aber vielversprechendes Potenzial: Wer LLMs im großen Maßstab mit strukturierten Daten betreibt, kann mit diesem Ansatz erhebliche Kosten sparen – ohne die bestehende Infrastruktur umzubauen. Ein Middleware-Ansatz, der sich lohnt, auszuprobieren.
Weitere Informationen und Updates: Hugging Face – offizielle Website.
